Motion Detection in aerial image pairs
Motion Detection in Aerial Image Pairs
This page introduces an approach on the detection of object motion regions in aerial image pairs with a Multi-Layer Markovian Model.
The article describing the main results appeared in IEEE Transactions on Image Processing, in 2009 [1]. The model has been partially presented in the IEEE ICIP07 conference [2]. A detailed research report can be found in [3] including several demonstrating figures, experiments, images etc. The test sets used for the evaluation (with ground truth) are available from our benchmark site (please ask for password by e-mail).
Abstract
In this work, we have proposed a probabilistic model for automatic change detection on airborne images taken with moving cameras. To ensure robustness, an unsupervised coarse matching is adopted instead of a precise image registration. The challenge of the proposed model is to eliminate the registration errors, noise and the parallax artifacts caused by the static objects having considerable height (buildings, trees, walls etc.) from the difference image. We describe the background membership of a given image point through two different features, and introduce a novel three-layer Markov Random Field (MRF) model to ensure connected homogenous regions in the segmented image.
Outline
In this paper, we propose a new multilayer MRF model to eliminate the registration errors and to obtain the true changes caused by object motions based on two input images. We extract two different features which statistically characterize the background membership of the pixels, and integrate their effects via a three-layer MRF. The proposed energy function encapsulates data dependent terms as well, which influence directly or - through the interlayer interactions - indirectly all labels in the model during the whole optimization. Contribution of the proposed method focuses on two aspects. First, we choose efficient complementary features for the change detection problem and we support the relevancy of their joint usage by offering experimental evidence. Here the probabilistic description of the classes is given by different feature distributions. Second, we propose a new fusion model showing how data-driven and label-based inferences can be encapsulated in a consistent probabilistic framework providing a robust segmentation approach. At the end, we give a detailed qualitative and quantitative validation versus recent solutions of the same problem and also versus different information fusion approaches with the same feature selection.
Registration and feature extraction
Formally, we consider frame differencing as a pixel labeling task with two segmentation classes: foreground (fg) and background (bg). Pixel belongs to the foreground, if the 3-D scene point, which is projected to a pixel in the first frame, changes its position in the scene's (3-D) world coordinate system or is covered by a moving object by the time taking the second image . Otherwise, the pixel belongs to the background. The procedure begins with coarse image registration using a conventional 2-D frame matching algorithm, which should be chosen according to the scene conditions. We use the Fourier shift-theorem based method for this purpose, since it proved to be the most robust regarding the considered image pairs.
Our next task is to define local features at each pixel which give us information for classifying as foreground or background point. Thereafter, taking a probabilistic approach, we consider the classes as random processes generating the selected features according to different distributions. The feature selection is shown in Fig. 1. The first feature is the gray level difference of the corresponding pixels in the two images. Using this feature, we can observe (Fig 1(d)) that several false positive foreground points are detected; however, these artifacts are mainly limited to textured "background" areas and to the surface boundaries. For the above reasons, we introduce a second feature which is derived from normalized block correlation between nearby image regions of the two layers. We see in Fig. 1(f) that the correlation descriptor alone causes also poor result: similarly to the gray level difference, a lot of false alarms have been presented. However, the errors appear at different locations compared to the previous case. First of all, due to the block matching, the spatial resolution of the segmented map decreases, and the blobs of object displacements become erroneously large. Second, in homogenous areas, the variance of the pixel values in the blocks to be compared may be very low; thus, the normalized correlation coefficient is highly sensitive to noise. In summary, the and features may cause quite a lot of false positive foreground points; however, the rate of false negative detection is low in both cases: they only appear at location of background-colored object parts, and they can be partially eliminated by spatial smoothing constraints discussed later. Moreover, examining the gray level difference, , results usually in a false positive decision if the neighborhood of is textured, but in that case the decision based on the correlation peak value is usually correct. Similarly, if votes erroneously, we can usually trust in the hint of the difference feature.
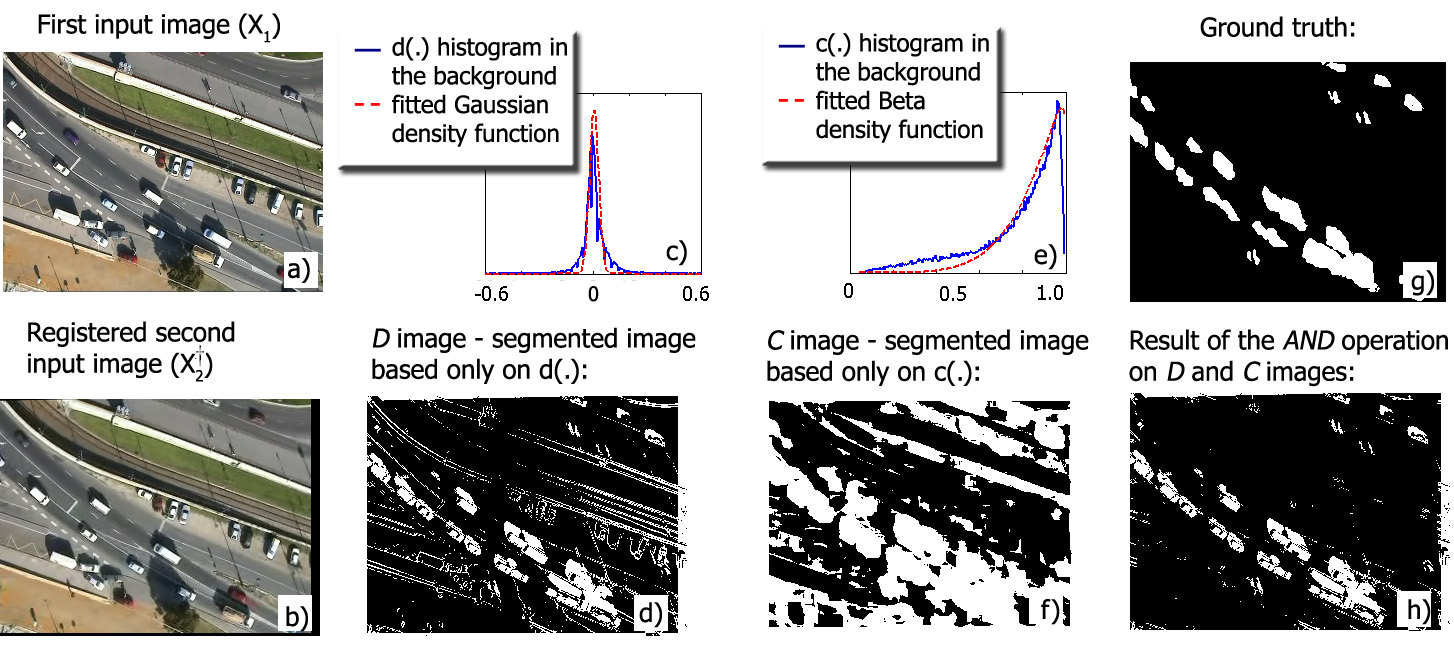 Fig. 1. Feature selection. (a) First input image (b) Registered second image (c) gray level difference feature statistics. (d) segmented image based only gray level difference (e) oncorreltation feature statistics. (f) image segmented image based only on correltation feature (g) Ground truth. (h) pixel-by-pixel fusion
Fig. 1. Feature selection. (a) First input image (b) Registered second image (c) gray level difference feature statistics. (d) segmented image based only gray level difference (e) oncorreltation feature statistics. (f) image segmented image based only on correltation feature (g) Ground truth. (h) pixel-by-pixel fusion
Mutli-layer MRF model
Since the seminal work of Geman and Geman, Markov random fields (MRF) have been frequently used in image segmentation, often clearly outperforming approaches with morphology-based postprocessing. For many problems, scalar valued features may be weak to model complex segmentation classes appropriately; therefore, integration of multiple observations has been intensively examined.
In the proposed approach, we construct a MRF model on a 3-layer graph. In the previous section, we segmented the images in two independent ways, and derived the final result through pixel by pixel label operations using the two segmentations. Therefore, we arrange the sites of into three layers Sd, Sc and S* each layer has the same size as the image lattice. We assign to each pixel a unique site in each layer. To ensure the smoothness of the segmentations, we put connections within each layer between site pairs corresponding to neighboring pixels of the image lattice. On the other hand, the sites at different layers corresponding to the same pixel must interact in order to produce the fusion of the two different segmentation labels in the S* layer, which is enforced by "interlayer" connections. We use first-order neighborhoods in the image lattice, where each pixel has 4 neighbors. Therefore, the graph has doubleton "intralayer" cliques which contain pairs of sites, and "interlayer" cliques consisting of site-triples.We also use singleton cliques, which are one-element sets containing the individual sites: they link the model to the local observations.
Experiments
The evaluations are conducted using manually generated ground truth masks regarding different aerial images. We use three test sets provided by the Hungarian Ministry of Defence Mapping Company©, which contain 83 image pairs. The time difference between the frames to be compared is about 1-3 s. The image pairs of the "balloon1" and "balloon2" test sets have been captured from a flying balloon, while images of the "Budapest" test set originate from high resolution stereo photo pairs taken from a plane. In the quantitative experiments, we investigate on how many pixels have the same label in the ground truth masks and in the segmented images obtained by the different methods. For evaluation criteria, we use the F-measure which combines Recall and Precision of foreground detection in a single efficiency measure.

Fig. 2 Motion mask results on the image pairs of the 'balloon 1' test set, with the proposed (3-layer) and reference models.
References
[1] Cs. Benedek, T. Szirányi, Z. Kato and J. Zerubia: ”Detection of Object Motion Regions in Aerial Image Pairs with a Multi-Layer Markovian Model”, IEEE Transactions on Image Processing, vol. 18, no. 10, pp. 2303-2315, 2009
[2] Cs. Benedek, T. Szirányi, Z. Kato and J. Zerubia: ”A Multi-Layer MRF Model for Object-Motion Detection in Unregistered Airborne Image-Pairs,” IEEE International Conference on Image Processing (ICIP), vol VI, pp. 141-144, presented as lecture, San Antonio, Texas, USA, September 16-19, 2007

[3] Cs. Benedek, T. Szirányi, Z . Kato and J. Zerubia , ”A three-layer MRF model for object motion detection in airborne images,” Research Report 6208 , INRIA Sophia Antipolis, France, June 2007